Column Transformer
Column Transformer은 여러 transformer 을 column에 좀 더 쉽게 적용하도록 한 클래스입니다.
😎 주요 메서드 탐구
sklearn.compose.ColumnTransformer(transformers, *, remainder='drop', sparse_threshold=0.3, n_jobs=None, transformer_weights=None, verbose=False, verbose_feature_names_out=True)
transformers: 적용하는 transformer의 리스트가 담긴 튜플을 의미합니다
Pipeline을 이용할 때와 마찬가지로 string 형태의 name과 transformer을 함께 전달할 수 있습니다.
remainder은 ColumnTranformer의 핵심적인 기능으로 dataframe 전체에 tranformer을 적용할건지, 적용하지 않는 컬럼은 drop 할건지 그냥 그대로 passthrough할건지 정하는 기능입니다.
remainder = 'drop'
remainder = 'passthrough'
remainder = 'drop' ( default 는 drop 입니다 )
예시 _
숫자형 요소)
>>> import numpy as np
>>> from sklearn.compose import ColumnTransformer
>>> from sklearn.preprocessing import Normalizer
>>> ct = ColumnTransformer(
... [("norm1", Normalizer(norm='l1'), [0, 1]),
... ("norm2", Normalizer(norm='l1'), slice(2, 4))])
>>> X = np.array([[0., 1., 2., 2.],
... [1., 1., 0., 1.]])
>>> ct.fit_transform(X)
array([[0. , 1. , 0.5, 0.5],
[0.5, 0.5, 0. , 1. ]])
문자열 요소)
공식 홈페이지에는 문자열인 요소들은 1차원의 array형태 적용을 통해 column transformer 적용이 가능하다고
명시되어있습니다
>>> from sklearn.feature_extraction import FeatureHasher
>>> from sklearn.preprocessing import MinMaxScaler
>>> import pandas as pd
>>> X = pd.DataFrame({
... "documents": ["First item", "second one here", "Is this the last?"],
... "width": [3, 4, 5],
... })
>>> ct = ColumnTransformer(
... [("text_preprocess", FeatureHasher(input_type="string"), "documents"),
... ("num_preprocess", MinMaxScaler(), ["width"])])
>>> X_trans = ct.fit_transform(X)
>>> X_trans.toarray()
array([[0. , 0. , 0. , ..., 0. , 0. , 0. ],
[0. , 0. , 0. , ..., 0. , 0. , 0.5],
[0. , 0. , 0. , ..., 0. , 0. , 1. ]])앞서 메서드에서 배운 것 처럼 (이름,transformer,적용 컬럼명)을 나열하면 번거롭게 scaler와 transformer을 따로 적용하지 않아도 한번에 이렇게 적용할 수 있습니다.
👀 make_column_transformer
이 클래스는 ColumnTransformer의 간편화된 버전으로 볼 수 있습니다. 메서드의 차이점은 위에
ColumnTransformer에 명시해야 했던 'name'이 생략되는 건데요
공식홈페이지의 예시를 보겠습니다.
>>> from sklearn.preprocessing import StandardScaler, OneHotEncoder
>>> from sklearn.compose import make_column_transformer
>>> make_column_transformer(
... (StandardScaler(), ['numerical_column']),
... (OneHotEncoder(), ['categorical_column']))
ColumnTransformer(transformers=[('standardscaler', StandardScaler(...),
['numerical_column']),
('onehotencoder', OneHotEncoder(...),
['categorical_column'])])
name이 없으니까 훨씬 코드가 짧고 명료해보이네요!
+ 추가 정리 (sklearn.compose.make_column_selector)
이 클래스는 ColumnTransformer 과 함께 사용할 수 있는 메서드로, 특정 데이터 타입의 컬럼을 쉽게 선택 하도록 해주는 기능을 합니다.
Make_column_selector 은 아래와 같은 변수들을 사용합니다
- pattern : 여기서 명시하는 regex 정규표현식 패턴이 포함된 컬럼명을 고르도록 합니다
- dtype_include: select_dtypes와 동일하게 어떤 데이터 타입을 포함할지 명시합니다
- dtype_exclude: select_dtypes와 동일하게 어떤 데이터 타입을 제외할지 명시합니다
>>> from sklearn.preprocessing import StandardScaler, OneHotEncoder
>>> from sklearn.compose import make_column_transformer
>>> from sklearn.compose import make_column_selector
>>> import numpy as np
>>> import pandas as pd
>>> X = pd.DataFrame({'city': ['London', 'London', 'Paris', 'Sallisaw'],
... 'rating': [5, 3, 4, 5]})
>>> ct = make_column_transformer(
... (StandardScaler(), make_column_selector(dtype_include=np.number)), # rating
... (OneHotEncoder(),make_column_selector(dtype_include=object))) # city
>>> ct.fit_transform(X)
array([[ 0.90453403, 1. , 0. , 0. ],
[-1.50755672, 1. , 0. , 0. ],
[-0.30151134, 0. , 1. , 0. ],
[ 0.90453403, 0. , 0. , 1. ]])
다양한 종류의 데이터 타입 전처리
이 내용은 공식홈페이지에서 내용이 너무 좋아서 가지고 왔는데요, 숫자형 데이터와 object 형태의 데이터를 좀 더 빠르고 간편하게 쓰고 싶다면 Pipeline과 ColumnTransformer 을 함께 사용할 수 있습니다.
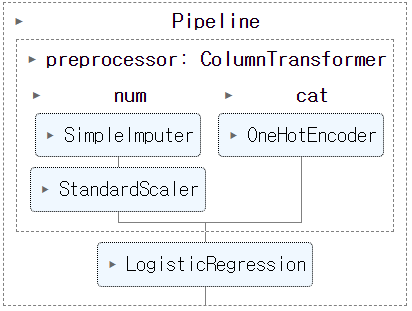
numeric_features = ["age", "fare"]
numeric_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler())]
)
#숫자형,카테고리형 피처 구분
#숫자형-> Pipeline 에 simpleimputer과 scaler사용
categorical_features = ["embarked", "sex", "pclass"]
categorical_transformer = OneHotEncoder(handle_unknown="ignore")
#카테고리형 => 원핫인코더 사용
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features),
])
ColumnTransformer 적용 후, Pipeline을 통해 모델 적용
clf = Pipeline(
steps=[("preprocessor", preprocessor), ("classifier", LogisticRegression())]
)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
clf.fit(X_train, y_train)
print("model score: %.3f" % clf.score(X_test, y_test))
언뜻 보면 복잡해보이지만 익숙해지면 정말 효과적으로 사용할 수 있을 것 같습니다!
Source:
https://scikit-learn.org/stable/auto_examples/compose/plot_column_transformer_mixed_types.html
https://scikit-learn.org/stable/modules/generated/sklearn.compose.ColumnTransformer.html
'Data Science > Machine Learning' 카테고리의 다른 글
| Train , Test 데이터 전처리를 위해 병합하는 방법 정리 ! (0) | 2022.10.13 |
|---|---|
| 카테고리형 데이터가 많을 시 고려사항 😮 (0) | 2022.10.13 |
| Dataframe describe 기능 정리 (0) | 2022.10.12 |
| [ Scikit-learn ] Train, test데이터 분리(train_test_split, StratifiedShuffleSplit) (0) | 2022.10.02 |
| [Scikit-learn] sklearn.feature_selection.SelectFrom Model (0) | 2022.09.23 |
댓글