이번에는 결정계수에 대해서 다뤄보겠습니다.
결정계수는 coefficient of determination 혹은 R^2 (R squared, R 제곱 통계량)라고 부르는데요
😎 결정계수의 사용 목적
회귀분석에서 추정한 모델이 얼마나 종속변수를 잘 설명하는지의 비율을 의미합니다.
여기서 '설명력'은 '분산'을 활용하여 통계모형의 설명력을 검증합니다.
✔ 결정계수의 개념
- 결정계수의 범위: 0 에서 1 사이
- 기본 틀 : 예측값의 분산/실제값의 분산
결정계수가 여러가지 통계 개념이 복합되어 있어서 처음에 이해하는데 좀 어려움이 있는 것 같습니다.
필요한 개념을 하나씩 정리하면서 결정계수를 이해해 보겠습니다.
결정계수가 분산을 기본으로 한다고 하는데 그러면 분산이 뭐죠?
간단히 애기하면 분산은 값이 얼마나 퍼져 있는지 => 데이터가 얼마나 퍼져있는지에 대한 설명력 수치화
분산 = 편차**2의 평균 = E[(X-평균)]**2 = 평균에 대한 편차 제곱의 평균
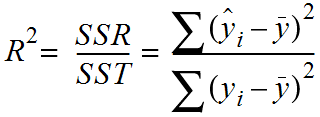
분산의 개념을 머리에 넣고 생각 해보면 이제 왜 결정계수가 예측값의 분산을 실제값의 분산으로 나눴다고 하는지
알 수 있습니다. 이제 공식 옆에 있는 SSR 과 SST를 알아보겠습니다.
우선 각 용어의 뜻은 아래와 같은데요
이름이 잘 와닿지는 않지만 제일 마지막 글자만 보면 좀 이해가 값니다
(^가 있는 y는 예측값 , -가 있는 y는 관측값의 평균을 의미합니다)
- SST : Total Sum of Squares
- SSE : Explained Sum of Squares
- SSR: Residual Sum of Squares

여기서 SST = SSE + SSR 이라고 하는데 왜 그런지 살펴보겠습니다.
아래처럼 우리의 예측값은 회귀선에 쭉 있고 관측값은 점으로, 일직선은 관측값의 평균으로 보겠습니다.
여기서 (관측값- 평균) = (관측값-회귀선의 예측값) + (예측값-평균)으로 이루어져 있습니다.
이 관계를 해석해보면 회귀로 예측을 진행했는데, 전체의 변동성 SST에서 회귀로 예측한 부분 SSR의 변동성이 얼마지? 라는 질문을 수치화한게 SSR/SST 즉 결정계수가 됩니다!!!

✔ 결정계수의 해석
결정계수는 전체 분산 중 예측값 분산의 비율이기 때문에 0에서 1 사이의 값을 가집니다.
그러면 1에 가깝다 -> 예측의 설명력이 높다는 의미이기 때문에 1에 가까울 수록 좋다고 볼 수 있습니다
✔ 결정계수의 활용 방법
회귀에서 지표를 활용하는 방법에는 크게 3가지가 있다고 설명드렸었는데요
2022.10.19 - [Data Science/Machine Learning] - 회귀 평가 지표 개념 A-Z 및 활용방법 이해하기
마찬가지로 결정계수도 sklearn.metrics API를 사용하는 방법과 교차검증에서 scoring 옵션을 설정하는 방법이 있습니다.
- sklearn.metrics.r2_score(실제값, 예측값)
- scoring = 'r2' (cross_val_score과 GridSearchCV 파라미터 옵션에 r2 입력)
'Data Science > Statistics' 카테고리의 다른 글
| 최대우도추정(MLE) 개념 총 정리 (0) | 2023.01.08 |
|---|---|
| 신뢰수준과 신뢰구간이란? (0) | 2023.01.03 |
| 부트스트랩(+배깅) 리샘플링 개념 정리 (0) | 2023.01.01 |
| 데이터사이언스의 '편향' 이란? (0) | 2022.12.30 |
| 분산과 표준편차의 통계적 의의/차이 (0) | 2022.12.29 |




댓글