딥러닝 코드를 보면서 배치 정규화를 위한 layer을 종종 보게 되었는데요
tensorflow.keras.layers.BatchNormalization
유용한 활용을 위해 배치 정규화란 무엇이고 언제, 어떻게 사용하는지 여러 자료를 참고해 정리해보겠습니다 :)
🧐 배치 정규화란?
이름 그대로 input을 0과 1 사이의 값으로 정규화 시켜주는 인공신경망의 층입니다.
그렇다면 왜 배치정규화가 필요할까요? 인공신경망에서는 훈련을 거듭할 수록, 인풋으로 들어오는 배치 데이터의 분포는 불규칙하고 사실상 랜덤하게 됩니다. 이렇게 데이터의 분포가 변하면,모델은 계속 새로운 데이터 분포에 대응하려 하면서 전반적인 훈련이 느려지는 현상이 발생하게 됩니다. 이때, 훈련을 계속하더라도 데이터의 분포를 유지시켜주는 일종의 구심점 역할을 배치 정규화가 하게 됩니다. 따라서, 훈련 속도가 늦춰지는 것을 막고 모델의 정확도와 안정성 역시 향상 시켜줍니다.
🤷♂️ 언제 배치 정규화를 사용하지?
배치정규화의 또 다른 순기능은 일종의의 규제(regularization) 역할을 한다는 점입니다. 0~1 사이의 분포로 유지시켜 주면서 과적합 되는 것을 방지할 수 있습니다.
배치정규화는 활성화층 이전, 이후 모두 사용가능한데요, 구글에 batch norm before after이라는 연관 검색어가 바로 뜰만큼 언제 배치 정규화를 적용해야 하는지는 의견이 분분한 것 같습니다.
실무에서는 활성화레이어 다음에 정규화를 적용하는게 좋다는 말도 있고, 머신러닝에서 유명한 Andrew Ng 교수님은 활성화 함수 전에 배치 정규화하는 것을 추천했다고 하네요. 별 차이가 없다는 사람도 있고... 실험 환경에 따라서 융통성 있는 사용이 필요할거 같네요.
🤷♂️ 어떻게 사용하지?
사용방식은 비교적 간단합니다. 하나의 층 형태로 BatchNormalization 을 추가해주기만 하면됩니다
예시)
...
model.add(BatchNormalization())
...
tf.keras.layers.BatchNormalization(
axis=-1,
momentum=0.99,
epsilon=0.001,
center=True,
scale=True,
beta_initializer='zeros',
gamma_initializer='ones',
moving_mean_initializer='zeros',
moving_variance_initializer='ones',
beta_regularizer=None,
gamma_regularizer=None,
beta_constraint=None,
gamma_constraint=None,
**kwargs
)
훈련중에 배치 정규화가 적용되면 기본적으로 아래와 같은 구조를 통해 정규화가 실행됩니다.
들어오는 batch의 평균, 표준편차를 활용해서 정규화를 하고 -> 구해진 값에 gamma를 곱하고 --> 베타를 더해주는 값이
배치 정규화의 결과값이 되는 것이죠! (앱실론 epsilon 이 붙어 있는 이유는 분모에 있는 값이 0에 도달하지 않도록 수학적 기능을 위해 추가한 녀석입니다)
gamma * (batch - mean(batch)) / sqrt(var(batch) + epsilon) + beta
*beta는 0으로 초기설정 gamma는 1로 초기설정
단, 공식홈페이지에도 나와있지만 훈련을 할 때와, 실제 예측울 할때 구동방식에 차이가 있습니다.
훈련할때 => 현재 배치 인풋 값의 평균과 분산이용
테스트할때 => 훈련동안 저장해뒀던 배치들의 moving average, moving variation 사용
실제 예측을 할때, 훈련때 사용되었던 각 배치별 평균과 분산 값을 저장하고 가져오는 일은 비용이 많이 들기 때문에 훈련때 저장해두었던 가장 최근의 moving average와 movinag variation을 가져온다고 합니다
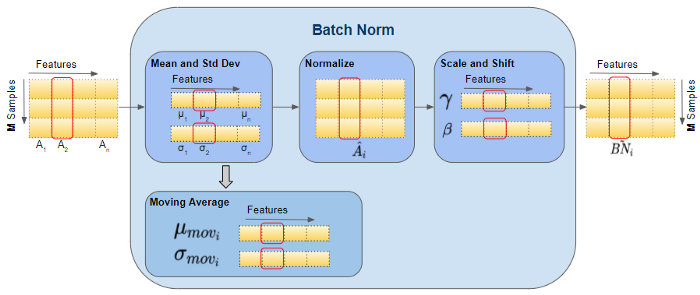
Ketan Doshi 님의 글에서 많이 배우고 전체적인 이해를 넓힐 수 있었는데요
만약 좀 더 자세한 설명을 보고 싶다면 사진 아래 링크를 정독해보시길 추천드립니다
Source:
https://forums.fast.ai/t/why-perform-batch-norm-before-relu-and-not-after/81293
https://www.tensorflow.org/api_docs/python/tf/keras/layers/BatchNormalization
'Data Science > Deep Learning' 카테고리의 다른 글
| Tensorflow 이미지 로드하는 방법 (0) | 2022.11.14 |
|---|---|
| Keras 텐서플로우 전이학습 모델 API 모음 (0) | 2022.11.14 |
| 구글 Colab에서 Pillow 설치하는 법 (0) | 2022.11.14 |
| Pytorch 주피터, 코랩, 아니콘다에서 버전 확인하기 (0) | 2022.11.13 |
| GAN 모델 구현 사이트 추천 (0) | 2022.11.12 |
댓글