ResNet(Residual Network)에 등장하는 Residual Block 의 개념과
왜 'Residual Block'을 사용하는지 알아보겠습니다.
1. Residual Block이란?
[Residual Block 등장 배경] 연구자들은 신경망의 층이 깊어질수록 얕은 신경망보다 성능이 뒤떨어진다는 사실을 발견했습니다. (아래 그래프처럼 layer이 더 많은 모델이 training error가 훨씬 심각함을 알 수 있습니다.)
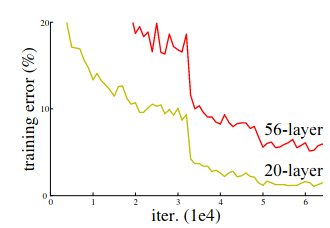
이론적으로는 층이 깊을 수록 성능이 더 좋아진다고 생각했으나, 실상은 그렇지 않았던 것이죠. 그래서 층이 깊어지더라도 앞서 학습한 층들의 정보를 잃지 않으며 성능을 높이기 위해 제시된게 Residual Block 입니다.
다른 자료를 보니 Residual block을 "skip-connection blocks that learn residual functions with reference to the layer inputs instead of learning unreferenced functions"으로 정의해두었는데요
Andrew Ng 교수님의 CNN 강의에서도 나오듯 Residual block의 핵심은 layer간의 연결을 건너뛰어서 연산한다는 Skip Connection 입니다.

skip connection 개념을 신경망의 층 관점에서 보겠습니다. input을 x라고 할 때, 순방향적으로 전달되어 나오는 F(x)에 skip connection한 x를 더하는 F(x)+x가 Residual connection입니다. 식 자체는 간단하쥬? (그림 옆의 identity는 x 가 I(x) 항등함수 x로도 표현가능하기 때문에 identity로 표기되어 있습니다)

그렇다면 여기서 Residual이라는 말은 어디서 나온 걸까요?
x를 input, H(x)를 x의 분포로 가정하면 Residual 은 최종구하고자 하는 H(x)와 input의 차이로 볼 수 있습니다
R(x) = Residual = Output - Input = H(x) - x
항을 넘겨서 방정식을 정리해보면 위 그림과 유사한 식이 나오죠?
H(x) = R(x) + x
위 신경망 층(F(x) +x)에서는 F(x)가 R(x) 의 역할을 하기 때문에 Residual block 으로 불리는 것이죠!
**참고**
Andrew Ng 교수님의 강의에서는 ResNet에 적용된 Residual block을 2가지 형태로 소개하고 있습니다.
단순히 x를 통해 연결을 skip 한 형태 (skip connection = identity shortcut connection), 그리고 연결을 건너뛸 때 또 다른 합성곱 층을 적용한 형태인데요. 아래 그림을 통해 구조를 참조해보면 좋을 것 같습니다.
Identity Block

Convolutional Block

2. Residual Block 사용 효과
- 그레디언트 소실 문제 완화
그레디언트 소실 문제는 은닉층의 깊이가 깊어질 수록 연쇄적으로 계산되는 가중치의 손실함수에 대한 그레디언트 값이 극도로 작아져서 역전파(Back Propagation)가 제대로 실행되지 않는 문제를 의미합니다.
이때 Residual block 을 적용하면 x, x+1, x+2 층에서 x+2는 x+1 (직전 층) 뿐만 아니라 x로부터 정보를 받게 되죠, 그러면 역전파를 실행할 때 어느정도 값이 극도로 작아지는 것을 막아주는 효과가 일부 발생합니다. (자세한 내용은 제목의 파란색 링크를 참조해주세요) 하지만, 여러 자료를 보면 ResNet, Residual Block의 주된 목적이 그레디언트 소실 문제 완화가 아니기 때문에 일부 완화하는 효과는 있으나, 절대적이지는 않다고 합니다.
(그레디언트 소실 문제가 완화됨에 따라, 신경망의 깊이가 깊어져도 성능이 떨어지지 않는 것을 Andrew Ng교수님 강좌에서는 "makes it easier for the block to learn an identity function"으로 표현했습니다.)
참고자료:
https://towardsdatascience.com/residual-blocks-building-blocks-of-resnet-fd90ca15d6ec
https://ai.stackexchange.com/questions/30375/residual-blocks-why-do-they-work
https://paperswithcode.com/method/residual-block
https://ai.stackexchange.com/questions/17764/why-do-resnets-avoid-the-vanishing-gradient-problem
'Data Science > Deep Learning' 카테고리의 다른 글
| 경사하강법 Python 파이썬 코드로 구현하기 (0) | 2023.01.13 |
|---|---|
| 1*1 합성곱층 (Convolution layer) 원리 및 목적 설명 (1) | 2022.12.22 |
| CNN 합성곱 신경망 Flatten Layer의 역할 및 방법 (0) | 2022.11.30 |
| 파일에서 랜덤한 이미지 시각화 하는 법 (OpenCV) (0) | 2022.11.22 |
| 구글 코랩 Colab 에서 cv2.imshow 오류 해결방법 (0) | 2022.11.21 |



댓글