사실 분산과 표준편차는 중학교때부터 용어는 들어왔지만, 왜 데이터 사이언스에서 이 2개의 개념이 빠지지 않는지 어떤 의미를 가지고 있는지 살펴보려합니다.
✔ 변이추정을 위한 분산/표준편차
데이터를 2차원으로 표현하면 하나의 점으로 표현되는데요. 이처럼 데이터의 위치는 데이터에 대한 주요한 정보를 가지고 있습니다. 이때 데이터가 얼마나 퍼져 있는지 산포도(dispersion= spread = scatter), 즉 데이터의 변이(variability) 추정을 위한 값이 '분산'과 '표준편차'입니다.
데이터가 얼마나 퍼져 있는지를 알려면 무엇을 기준으로 얼마나 퍼져있는지에 대한 개념이 필요합니다. 여기서 등장하는 개념이 '편차'입니다. 여기서 이 2개의 개념 역시 { 추정값 - 관측값 } = 편차를 근간으로 하는데요. 이때 평균에 대한 편차 { 추정값 - 평균값 } 을 구하면 데이터가 평균을 기준으로 얼마나 퍼져 있는지를 알려주게 되겠죠.
이제 한번씩은 봤을 법한 분산과 표준편차의 공식을 보겠습니다.
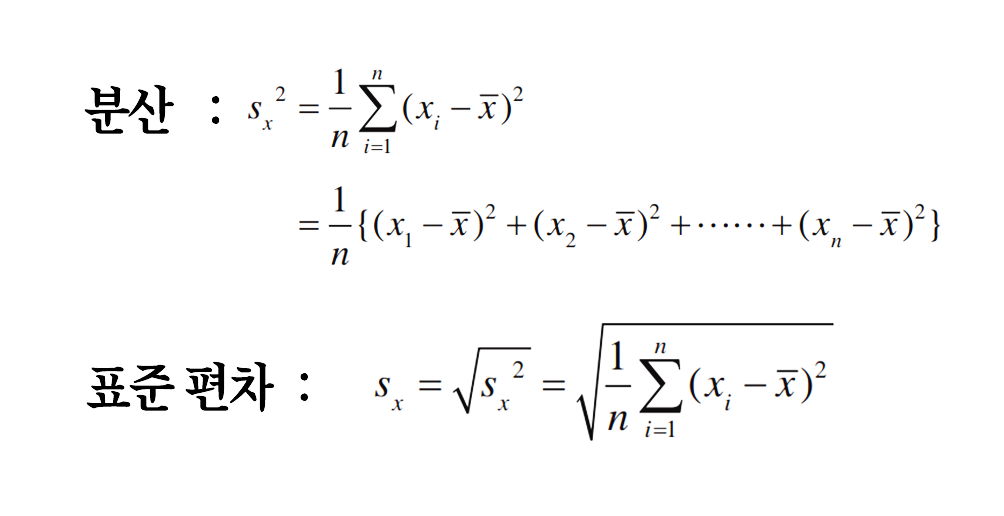
편차를 알고나서 보면 분산은 평균에 대한 편차 제곱의 평균을 했음을 알 수 있습니다.
'제곱편차'를 사용해 변이 추정을 이용한 방식인데요
✔ 분산과 표준편차의 차이
간혹 면접에서 나오는 질문으로, 분산과 표준편차의 차이는 뭘까요?
분산과 표준편차의 가장 큰 차이는 '해석력'입니다. 표준편차는 루트를 취하면서 원래의 데이터셋과 같은 척도(same scale = same unit)에 있기 때문에 얼마나 데이터가 퍼져있는지를 더욱 직관적으로 전달합니다.
*추가/수정해야 할 내용이 있으면 코멘트 남겨주세요!
'Data Science > Statistics' 카테고리의 다른 글
| 최대우도추정(MLE) 개념 총 정리 (0) | 2023.01.08 |
|---|---|
| 신뢰수준과 신뢰구간이란? (0) | 2023.01.03 |
| 부트스트랩(+배깅) 리샘플링 개념 정리 (0) | 2023.01.01 |
| 데이터사이언스의 '편향' 이란? (0) | 2022.12.30 |
| 결정계수 R-squared 개념 및 응용 정리 (0) | 2022.10.20 |




댓글