누군가가 편향에 대해 설명해보세요 라고 질문한다면, 뭔지는 어렴풋이 알지만 명료하게 대답하기는 어렵기 때문에
한번 정리하고 넘어가려 합니다. 데이터 분석에서 빠지지 않는 질문 편향은 뭘까요?
편향이란?
편향이라는 단어 자체는 일상에서도 '편향적인 사람' '편향적이다' 등등 많이 사용하는 표현입니다. 일상 속에서는 어떠한 방향으로 치우친 경향을 설명할 때 많이 언급됩니다. 그러면 통계적인 측면에서 편향은 어떻게 정의될까요? 데이터사이언스를 위한 통계 책에서는 '통계적 편향은 측정 과정 혹은 표본추출 과정에서 발생하는 계통적인(systematic) 오차를 의미한다' 라고 정의했습니다. 이와 유사하게 위키피디아에서는 '결과와 사실 간의 차이를 유발하는 체계적인 경향을 의미한다'고 하는데요. 2가지 정의 공통적으로 통계적 실험 과정에서 어떠한 원인으로 발생하는 계통적인 오차를 의미한다는 정의를 내리고 있는데요.
오차는 알겠는데 계통적인 오차가 뭘까요? 계통오차란, 오차의 발생 원인을 파악할 수 있어서 수식에 의해 보정이 가능한 측정가능한 오차를 의미합니다.
*오차의 종류 => 계통적오차(측정가능한 오차) + 우연오차(측정불가능한 오차)
머신러닝/딥러닝에서 편향의 역할
편향의 일반적 개념에서 나아가서 머신러닝/딥러닝에서 편향의 역할에 대해 탐구해보겠습니다. 편향은 1980 년 'The need for biases in learning generalizations'에서 처음 소개되었습니다. Tom M.Mitchell은 모델에 편향의 개념을 도입함으로써 방대한 데이터에 더 일반화 할 수 있고 robust 할 수 있다는 아이디어를 제시했는데요. 이 개념이 소개된 이후, 편향은 y = wx + b 같은 선형회귀식과 딥러닝의 편향 뉴런의 형태로 예측을 위해 응용되고 있습니다.
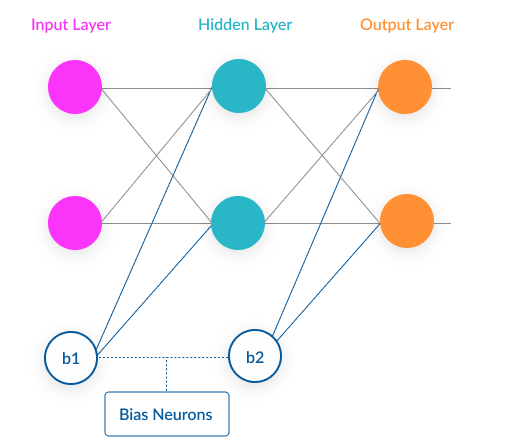
머신러닝과 딥러닝에서 편향은 우리가 없애야 하는 하나의 오차보다는, 모델의 유연한 학습을 위한 하나의 기능적인 역할을 하는데요. 가령 분류를 수행해야 할때, 예측을 한다는 것은 데이터 포인트들을 효과적으로 분리할 수 있는 초평면(hyperplane)을 찾는 문제로 해석할 수 있는데요. f(x) = wx로 편향이 없는 형태라면, (0,0)을 반드시 지나며 위 아래로 이동할 수 없는 한계점이 있습니다.

하지만 여기서 b 편향을 더해주게 되면 위 아래로 이동이 가능하죠! 위 아래로 이동이 가능하다는 것은 효과적으로 공간을 탐색해서 우리가 찾는 최적의 초평면을 찾을 수 있음을 의미합니다.
*수정/추가할 사항이 있으면 코멘트 남겨주세요!
'Data Science > Statistics' 카테고리의 다른 글
| 최대우도추정(MLE) 개념 총 정리 (0) | 2023.01.08 |
|---|---|
| 신뢰수준과 신뢰구간이란? (0) | 2023.01.03 |
| 부트스트랩(+배깅) 리샘플링 개념 정리 (0) | 2023.01.01 |
| 분산과 표준편차의 통계적 의의/차이 (0) | 2022.12.29 |
| 결정계수 R-squared 개념 및 응용 정리 (0) | 2022.10.20 |




댓글