신뢰구간(Confidence interval)이란?
신뢰구간은 구간 추정을 통해 모수가 포함될 추정값을 제시하는 방법을 의미합니다. '이 구간 안에는 모수의 추정값이 있을 것이다' 라는 추측을 할 때 사용되는 개념이라는 건데요. 그러면 이 개념을 왜 사용할까요? 이는 표본이라는 것 자체가 랜덤샘플링을 통해 추출되어 '불확실성'을 내재하고 있기 때문인데요. 이 때문에 '신뢰구간'을 제시함으로서 표본을 활용한 추정의 잠재적인 오류를 제시하거나 표본의 크기가 더 커져야 하는지 여부에 대한 정보를 알려주는 것이죠.
신뢰수준(Confidence level)이란?
신뢰'구간'과 신뢰'수준'은 어휘에서 의미 구분이 가능합니다. 신뢰구간은 A에서 B라는 하나의 범위를 나타내고 신뢰수준은 '신뢰구간에 모평균값이 포함될 확률' = 몇%의 신뢰수준이라는 확률을 의미합니다.
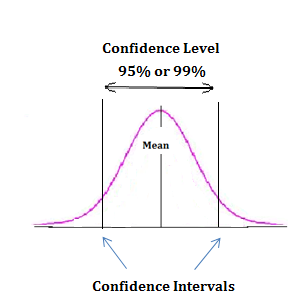
95%의 신뢰구간
=>"같은 모형에서 반복해서 표본을 얻고, 신뢰구간을 얻을 때 신뢰구간이 참 모수값을 포함할 확률이 95%가 되도록 만들어진 구간"
(출처 :실리콘밸리 데이터과학자가 알려주는 따라하며 배우는 데이터 과학)
이해한 내용을 기반으로 몇가지 중요한 체크리스트를 점검해보겠습니다.
- 허용할 수 있는 신뢰수준이 낮을 수록 신뢰구간은 좁아진다
- 부트스트랩은 신뢰구간을 구성하는 효과적인 방법이다
- 신뢰구간이 좁을 수록 모평균의 추정치가 정확해진다
- 표본크기가 클 수록 신뢰구간이 줄어든다 = 데이터가 많을 수록 표본 추정치의 변이가 줄어든다
= 모수 추정의 정확도는 sqrt(n)에 비례한다
= 표본의 크기가 커지면 커질수록 신뢰구간의 크기는 줄어들고, 줄어드는 속도는 sqrt(n)이다.
특히 마지막 체크리스트의 표본의 크기가 클 수록 표본 추정치의 변이가 줄어든다는 항목은 표준오차와 큰 연관성이 있는데요. 일반적으로 95%의 신뢰구간을 구할 때, 정규분포 상에서 평균값 기준 2*표준편차의 범위를 95%로 간주하는데요. 하지만 우리는 모수를 알수가 없기 때문에 표본평균에서 2*표준오차(SEM) 범위를 사용해 신뢰구간을 계산합니다. 표준오차는 표준편차를 표본크기의 루트값을 나눠 계산하기 때문에, 표본의 크기가 클수록 신뢰구간의 크기가 좁아지는 것입니다.
**표준편차와 표준오차
표준편차는 모집단의 분포가 얼마나 퍼져있는지 => 개별 데이터 포인트의 변동성
표준오차(Standard Error of Mean= 표본통계량의 표준편차)는 평균의 추정치에 대한 불확실도 => 표본 측정지표의 변동성

**수정/추가 필요시 댓글 남겨주세요
참고자료:
https://angeloyeo.github.io/2021/01/05/confidence_interval.html#fn:3
데이터사이언스를 위한 통계
실리콘밸리 데이터과학자가 알려주는 따라하며 배우는 데이터 과학
https://ko.wikipedia.org/wiki/%EC%8B%A0%EB%A2%B0_%EA%B5%AC%EA%B0%84
'Data Science > Statistics' 카테고리의 다른 글
| 최대사후추정(MAP) 개념 및 최대우도추정(MLE)과 비교 (0) | 2023.01.09 |
|---|---|
| 최대우도추정(MLE) 개념 총 정리 (0) | 2023.01.08 |
| 부트스트랩(+배깅) 리샘플링 개념 정리 (0) | 2023.01.01 |
| 데이터사이언스의 '편향' 이란? (0) | 2022.12.30 |
| 분산과 표준편차의 통계적 의의/차이 (0) | 2022.12.29 |




댓글