처음에 이 개념을 접하고 용어가 어렵다고 생각했는데 하나씩 뜯어보면서 개념을 정리해보려합니다. 먼저, MLE는 영어 뜻은 'Likelihood 를 최대화하는 추정방법'입니다. 그럼 Likelihood(가능도 = 우도)가 뭔지 알아봐야겠죠.
Likelihood란?
통계학상으로 Likelihood란 확률분포X의 모수θ가 어떤 확률변수의 표집값x와 일관된 정도를 나타냅니다 (출처:위키백과) 우리가 모수에서 표본을 추출할 때, 뽑히는 표본은 데이터x가 같을 수도 있고 다를 수도 있죠. 그런데 표본X에서 우리가 찾는 값x가 나오는 likelihood가 얼마인지 알고싶습니다. Pθ(X=x) = 표본 X가 특정 x일 확률이얼마일까요?
이 질문을 수식화하고 바라보는 관점을 x중심이 아닌, θ의 관점으로 해석한게 가능도 함수입니다. 가능도 함수 L(θ | x) 에서 우측의 식을 먼저보겠습니다. 확률변수 X=(X1, X2,...Xn)가 있을 때, 모수 θ에 대한 확률변수X의 확률밀도함수는 Pθ(X) 로 표현할 수 있습니다. 그리고 각 확률분포를 곱한 결합확률밀도함수가 L(θ|x) = Pθ(X) = P(x|θ) 입니다. (곱셈을 할 수 있는 이유는 우리의 관측값이 모두 독립적이고 동일한 분포를 가짐을 전제했기 때문입니다)
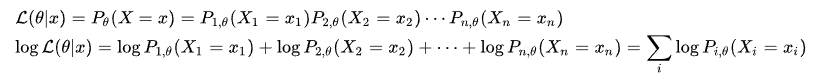
여기서 log를 취한 이유는 0과 1 사이에 존재하는 확률값을 L(θ|x)를 구하기 위해 확률간에 곱셈을 하면 우리가 구하려는 가능도가 0에 수렴하기 때문에 로그를 취해서 로그 가능도 함수를 사용합니다.
최대우도추정 (Maximum Likelihood Estimation) = argmax L(θ|x)
그럼 여기서 우리가 알아보려는 최대우도추정은 주어진 표본에서 가능도를 가장 최대화하는 모수를 찾는 법을 의미합니다. 위키백과에서는 최대우도법을 "어떤 확률변수에서 표집한 값을 토대로 그 확률변수의 모수를 구하는 방법" == "원하는 값들이 나오는 가능도를 최대로 만드는 모수를 선택하는 방법"으로 정의하고 있습니다.
이 개념이 중요한 이유는 가능도가 높음 > 우리가 뽑은 이 표본이 수집될 확률이 높다 > 우리의 모수가 실제값일 확률이 높다는 것을 의미하기 때문입니다. 그래서 딥러닝 논문을 읽다보면 종종 최대우도추정을 사용했다, 안했다 이런식으로 사용하는 데이터에 대한 설명을 해놓는 모습을 볼 수 있습니다.
✔ 오늘의 핵심 정리
- 가능도 함수는 모수 θ를 추정할 때 사용된다
- 가장 가능도가 높은 모수를 사용한다 ---방법--> MLE 최대우도추정
다음에는 MLE와 함께 언급되는 유사하면서 다른 개념인 MAP를 다뤄보겠습니다
피드백이나 추가 정리해야 하는 사항이 있으면 알려주세요~~~
'Data Science > Statistics' 카테고리의 다른 글
| P-값 의 개념 및 오해와 진실 정리 (0) | 2023.01.17 |
|---|---|
| 최대사후추정(MAP) 개념 및 최대우도추정(MLE)과 비교 (0) | 2023.01.09 |
| 신뢰수준과 신뢰구간이란? (0) | 2023.01.03 |
| 부트스트랩(+배깅) 리샘플링 개념 정리 (0) | 2023.01.01 |
| 데이터사이언스의 '편향' 이란? (0) | 2022.12.30 |



댓글