🧐 DataFrame 이란?
Pandas에서는 DataFrame을 여러 다른 타입의 컬럼을 가진 2차원의 데이터 구조로 정의하고 있습니다
처음에 저도 DataFrame이라는 개념을 들었을 때 잘 이해가 안 갔는데요
간단히 생각하면 엑셀의 피벗테이블, 일반 표 등 말그대로 Data를 담은 Frame이다!
정도로 이해가능 할 것 같습니다
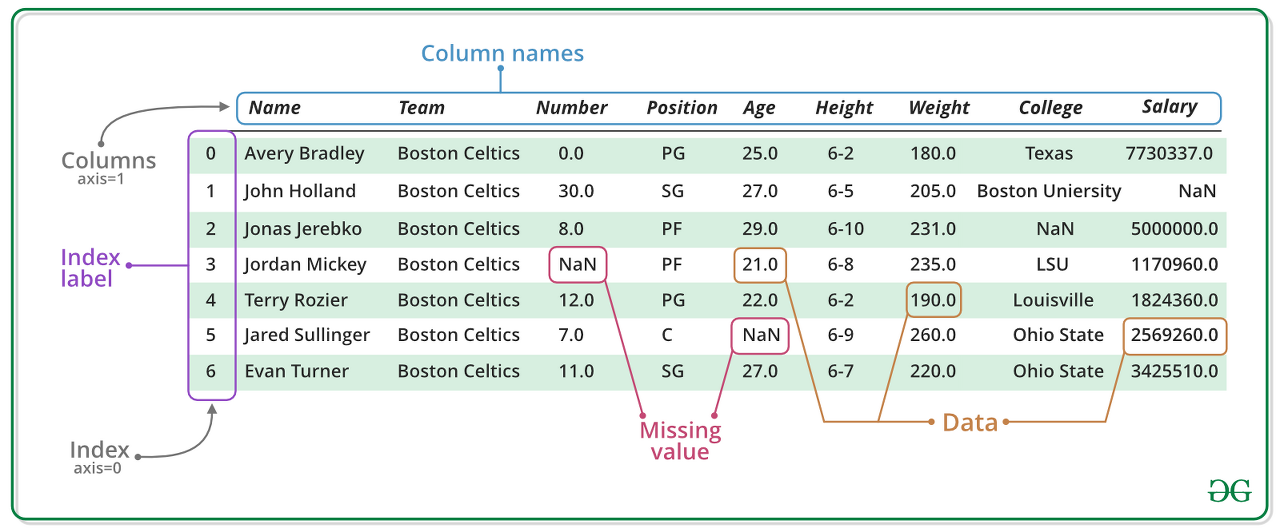
여기서 반드시 짚고 넘어가야 하는 부분은 DataFrame과 관련된 기본 용어인데요
DataFrame은 반드시 가장 왼쪽에 index label 이 있고
열이름이 위쪽에 위치해 있습니다
일반적으로 행은 axis = 0, 열은 axis =1로 표현합니다
여기서 데이터프레임의 한 줄, 즉 열 데이터는 Series로 지칭되니 꼭 기억하시길 바래요!
✨ DataFrame 만들기
1) Dict 형식 직접 입력 방식
import Pandas as pd
pd.DataFrame({'열1이름' :[value1,value2,..value값],'열2이름' :[value1,value2,..value값]..})
이런식으로 주로 문자열 형태의 열이름: 들어갈 값들을 리스트 형식으로 나열하면 됩니다
2) 중첩리스트 이용 방식
pd.DataFrame([값을 넣은 중첩 리스트], index = [인덱스값], columns=[열이름 리스트])
이 방법은 전체 데이터 프레임을 통으로 그려준다고 보면 됩니다
df = pd.DataFrame([[ 1,2,3].[4,5,6],[7,8,9]], index=[1,2,3], columns = ['a','b','c'])
이런식으로 데이터 값들을 앞에 넣고 index값을 주고 열이름을 지정합니다
** 데이터프레임 index 지정방식
index는 단순히 index = [1,2,3] 처럼 넘버링으로 지칭도 가능하지만, 데이터가 많아지면 사실 단순히 숫자를 나열하면
비효율성이 발생합니다. 때문에, range(1,3), np.arange(1,6), np.arange(1,10,2),
pd.date_range('2022-12-25',periods=5)처럼 다양한 표현이 가능합니다
만약, 인덱스를 데이터 프레임에 포함시키고 싶지 않다면 ignore_index =True로 지정하면 됩니다
3) Series 시리즈 모으기
pd.DataFrame([Series1,Series2,Series3])
데이터프레임은 곧 Series의 모음으로 볼 수 있기 때문에 위와 같은 구성이 가능합니다
✨ DataFrame 조회 방법
단일 컬럼(열) 조회 ==> df['컬럼명']
다중 컬럼(열) 조회 ==> df[['컬럼명1','컬럼명2'...]]
조회 방법은 비교적 간단하지만 다중컬럼에서 [[ ]] 괄호가 2개인건 꼭!!!! 기억하셔야 합니다
처음 Kaggle할때 제일 헷갈리고 실수 많이 했던 부분이여서 간단하지만 중요한 것 같습니다
‼ DataFrame 조건 조회 방법
df.loc[라벨 기반조건] => 조건으로 문자(열이름)이 들어간다
df.iloc[인덱스 위치 기반 조건] => 조건으로 숫자가 들어간다
가장 빈번히 사용하고 빅데이터 분석기사 시험에 꼭 등장하는 녀석인데요
사실 이 둘 중에 뭘 사용하느냐는 상황에 따라 선택하면 됩니다.
하지만, 둘의 차이점과 활용법을 잘 알아둬야 나중에 헷갈리지 않는 것 같아요
df.loc 수행 형태
- loc은 df.loc[ ['s1','s2'] ] 처럼 s1과 s2행을 반환하는 단일 Series혹은 dataframe 반환
- df.loc['s1':'s5'] 처럼 s1행에서 s5행까지 슬라이싱 반환
- df.loc[[True,False,True]]처럼 True인 행만 반환하는 boolean 반환
- df.loc[행이름, 열이름] 행열 반환
df.iloc 수행 형태
- df.iloc[1] 처럼 2번째 행을 반환하라는 Series 반환
- df.iloc[[0,2]]처럼 첫번째에서 3번째 행을 데이터프레임 형태로 반환
- df.iloc[0:2] 처럼 첫번째에서 3번째 행을 슬라이싱으로 반환
- df.iloc[[True,False,True]]처럼 True인 행만 반환하는 boolean 반환
- df.iloc[행번호, 열번호]를 통해 값을 반환하는 행열반환
여기서 중요한건 loc 과 iloc 슬라이싱 반환을 실행할 때
['a':'c'] 처럼 문자로 슬라이싱을 하면 끝 c행이 포함되지만
[0:2]처럼 숫자로 슬라이싱을 하면 파이썬 슬라이싱처럼 끝값의 앞에 값 까지만 포함됩니다
'Data Science > Pandas, Numpy' 카테고리의 다른 글
| [ Pandas ] corr 상관관계수 반환 모듈 알아보기 (0) | 2022.10.01 |
|---|---|
| [ Pandas] 데이터프레임 align 알아보기 (0) | 2022.10.01 |
| [Numpy] Flatten 기능 및 사용법 정리 (0) | 2022.09.29 |
| [Numpy] 열 Column간 순서, 위치 바꾸기 (0) | 2022.09.29 |
| [Numpy] 넘파이 범용/유틸리티 함수 정리 (0) | 2022.09.28 |

댓글