*본 게시물을 Andrew Ng 교수님의 딥러닝 강의를 복습/정리를 위해 작성했음을 밝힙니다
Binary Classification
X.shape = (n,m)
Y.shape = (1,m)
Logistic Regression
로지스틱 회귀는 x라는 데이터들이 있을 때, 목표로 하는 분류값 y가 무엇이 될까?라는 질문에 활용됩니다.
가령 y라는 값이 1이 되는 확률을 얼마일까?를 식으로 나타내면 이와 같은데요 : ŷ = P(y=1 | x)
이 질문에 대한 답을 찾기 위해서 기본적으로 일반 회귀식을 떠올려보면 이 질문은 w와 b라는 회귀식의 변수와 필수적으로 연관되어 있음을 알 수 있습니다. 이때, 예측값 ŷ 을 찾기위해 선형회귀처럼 wx + b 형태로 접근할 수도 있지만,
0이냐 1이냐 같은 분류의 문제에서는 ŷ 이 하나의 확률로 나와야 하기 때문에 S(ŷ )= S(wx + b) 에 시그모이드 함수를 취함으로서 0.5를 기준으로 0 또는 1으로 분류되도록 하여 적용될 수 있도록 한 것이 로지스틱 회귀의 근본적인 접근입니다.
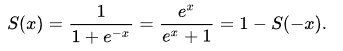

이제 w와 b를 찾기 위해서는 어떻게 찾지?라는 질문이 떠오르게 되는데요
여기서 등장하는게 Logistic Regression의 Cost 비용함수입니다.
(Costfunction을 최소화하는 w와 b를 찾는 것이 훈련의 목적)
Loss(error) function
L(ŷ ,y) = - (ylogŷ + (1-y)log(1-ŷ ))
손실함수는 수학적으로 L(ŷ ,y) 로 표현되는데요 (ŷ와 y의 Loss Function)
y = 1이면 L(ŷ ,y) = - logŷ ==> ŷ 최대화
y = 0 이면 L(ŷ ,y) = - log(1-ŷ) ==> (1-ŷ) 최대화 = > ŷ 최소화
Cost function
J(w,b) = 1/m Σ L(ŷ ,y) = -1/m Σ (ylogŷ + (1-y)log(1-ŷ ))
=> 각 Loss function의 평균
Gradient Descent
위 개념들의 연장선상에서, 많이 들어봤던 경사하강법을 이해할 수 있습니다. 그레디언트 디센트란, Cost function이 최소화되는 w와 b의 지점을 경사가 가파른 (가장 효과적인) step 을 통해 찾아나가는 것으로 해석할 수 있습니다. 이를 수식으로 나타내면 아래 필기처럼 나타낼 수 있습니다.
학습 과정에서 w의 값을 기존 w에서 경사(Cost function의 편미분값)을 업데이트 해가면서 최적의 w를 찾는 것이죠!


Source: DeepLearning.AI
This post is for the personal academic purpose
댓글