최대사후추정(Maximum A Posteriori)의 사후확률이란?
사후추정이 뭘 의미하는지부터 보겠습니다. 보통 우리가 표본을 뽑는다 라고 했을 때,
모수(θ)에서 표본 x를 뽑는다 라는 θ -> x 의 순서가 자연스럽게 느껴집니다. 그러면 여기서 θ는 사전에 우리가 알고 있는 값이 되고, x는 그 이후에 나오는 값이 되는 선후관계가 생깁니다. 그래서 우선적으로 P(θ)와 P(x|θ)를 아래와 같이 규정하고 가겠습니다.
P(θ) 사전확률밀도함수(Prior Probability Density Function)
P(x|θ) 파라미터θ가 주어질 때 표본 x의 확률
이제 여기서 질문을 질문을 거꾸로 해보겠습니다. 그러면 (x -> θ) 표본 x가 주어질 때 파라미터 θ를 구할 확률은? P(θ|x)
이게 바로 사후확률밀도 함수입니다. 사후확률밀도함수는 베이즈 정리를 기반으로 아래와 같이 풀어 쓸 수 있습니다.
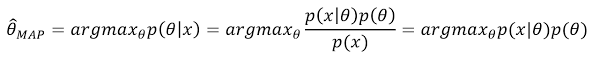
P(θ|x) = P(θ,x) / P(x) = {P(x|θ)*P(θ)}/P(x)
= (우도확률*사전확률)/증거 = (Likelihood*Class Prior Probability)/Predictor Prior Probability
우리가 사후확률을 최대화시킨다고 할 때, P(x)는 θ에 영향을 받지 않기 때문에 argmax P(x|θ)P(θ)로 표현가능합니다.
- MAP와 MLE 비교
MLE와 MAP는 둘 다 모수(θ) 를 추정한다는 공통점이 있습니다. 그러나, MLE와 MAP의 가장 큰 차이는 MAP의 P(θ) 사전확률입니다. MLE에서는 사전확률이 균일하다고 전제하는 반면, MAP는 사전확률에 대한 고려를 포함합니다.
관측값만을 사용하는 MLE는 극단값에 대해 좀 더 민감한 반면, 사전확률을 고려하는 MAP는 사전확률을 포함하기 때문에 MLE의 단점을 보완했다고 표현하는 것 같습니다. 그러나, 사전확률이 절대적이지 않기 때문에 이 사전확률의 신뢰도가 중요하다는 양날의 검 같은 비판도 있습니다.
MLE개념 정리는 아래 게시물을 참고하세요
2023.01.08 - [Data Science/Statistics] - 최대우도추정(MLE) 개념 총 정리
'Data Science > Statistics' 카테고리의 다른 글
| P-값 의 개념 및 오해와 진실 정리 (0) | 2023.01.17 |
|---|---|
| 최대우도추정(MLE) 개념 총 정리 (0) | 2023.01.08 |
| 신뢰수준과 신뢰구간이란? (0) | 2023.01.03 |
| 부트스트랩(+배깅) 리샘플링 개념 정리 (0) | 2023.01.01 |
| 데이터사이언스의 '편향' 이란? (0) | 2022.12.30 |



댓글